
A fascinating paper was recently published titled “Stealing Part of a Production Language Model.” In the paper, the authors present the very first attach technique for stealing models that can extract the complete embedding projection layer of proprietary production transformer language models like ChatGPT or PaLM-2. The paper details how an attacker can attack these models to reveal intellectual property of organizations that have deployed these models. The team achieves this by recovering the last embedding projection layer of a transformer based model through typical API access (as a consumer would do) without any backdoors, injection payloads, etc. Needless to say, the impact of this technique is far-reaching and capable of dramatically impacting an organization’s intellectual property, financial bottom line, and overall brand reputation.
Let’s unpack the details of this paper to illustrate what this means
The researchers found a way to learn some private details about certain AI language models, even when those models are only accessible through a restricted public interface and the model’s architecture and training data are kept secret. Specifically, they were able to figure out the size of a hidden layer inside the neural network – kind of like learning the number of neurons in the model’s “brain.” They did this by making a bunch of queries to the public model interface and examining the outputs statistically to infer information about the model’s inner structure.
In some cases, they were even able to recover the numerical values of the last layer of the neural network just before it outputs a prediction. This is still only a small part of the huge neural networks used in language models, but it’s more than was previously thought possible to extract. The researchers liken this to a “model stealing” attack. Companies invest a lot of resources into developing these large language models and want to protect their intellectual property. Being able to extract even pieces of the model is concerning from that perspective.
There are also potential risks if attackers could build on these techniques to extract even more sensitive information from the model, although the current attack is still quite limited. The researchers informed the AI companies and worked with them to help develop defenses and mitigations to make this kind of model stealing harder or more expensive to carry out in the future.
In summary, this research demonstrates a new way to peek inside the “black box” of certain AI models and steal parameters that were meant to be kept private. It has implications for protecting the IP of AI companies and highlights the need to develop models with security and privacy in mind to prevent more serious attacks. But for now, the attack is still quite constrained in what it can extract from these extremely large and complex models.
Let’s use a customer relationship management (CRM) service as an analogy to explain the main idea of the paper.
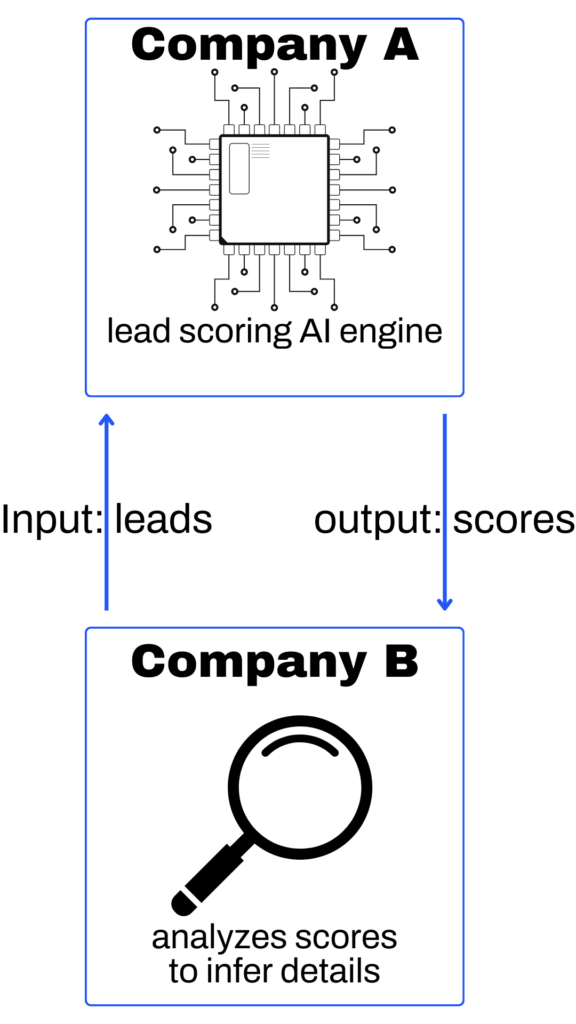
Imagine a leading CRM company (we’ll call them “Company A”) has developed a powerful AI-based lead scoring system that predicts the likelihood of a lead converting into a customer. This AI system is a key part of their service, and they keep the details of how it works a closely guarded secret to maintain their competitive advantage.
Now, let’s suppose that a rival CRM company wants to learn more about Company A’s lead-scoring AI. They can’t access the AI system directly, but they can sign up for an account with Company A and use the platform as a normal customer would.
The rival company could then feed many different leads into the system and observe the lead scores that the AI system outputs. By carefully analyzing the patterns in these scores, they might be able to infer some details about how the AI system works internally. For example, they might discover that the AI system likely considers certain factors more important than others in determining the lead score.
In this analogy:
- Company A’s lead scoring AI represents the language model.
- The lead scores output by the AI represent the language model’s outputs.
- The rival CRM company (Company B) represents the researchers trying to learn about the model.
- Inferring details about how the AI works based on the lead scores is like figuring out the size of the hidden layer and the numerical values of some parameters in the language model.
Company B attempts to infer details about Company A’s AI is analogous to the “model stealing” attack described in the paper. Company A wants to keep the inner workings of their AI system secret, just like AI companies want to protect the details of their language models. Company B’s success in inferring some aspects of how the lead scoring AI works suggests that Company A’s system may have some vulnerabilities. Similarly, the researchers’ ability to extract some information about the language models indicates potential security weaknesses. However, the rival company’s understanding of Company A’s AI is still limited – they don’t know all the details, just like the researchers can only extract a small part of the language model.
To prevent this kind of “attack,” Company A might need to add more security measures or change how their AI system works to make it harder to analyze and infer details. Similarly, AI companies may need to evolve their language models to be more resistant to this kind of partial extraction of their inner workings.
Let’s unpack the following quotes from the paper
“We also recover the exact hidden dimension size of the gpt-3.5-turbo model, and estimate it would cost under $2,000 in queries to recover the entire projection matrix”
In the context of this research, the “hidden dimension size” refers to the number of neurons in a specific layer of the neural network used in the GPT-3.5-turbo model. This layer is called the “embedding projection layer,” and it sits between the model’s main processing layers and the final output layer. The researchers were able to figure out the exact number of neurons in this layer for the GPT-3.5-turbo model by making a series of queries to the model’s API and analyzing the results. This is notable because the architecture details of GPT-3.5-turbo, including the size of its layers, are not publicly disclosed by OpenAI, the company that created the model. The second part of the quote relates to the cost of taking this “model stealing” attack a step further. The researchers estimate that by spending around $2,000 on API queries to GPT-3.5-turbo, they could recover the actual values of the “weights” in the embedding projection layer.
In a neural network, the weights are the learned parameters that determine how the model processes data. Recovering these weights would provide even more detailed information about the model’s inner workings beyond just the size of the layer.
The significance of this quote is twofold:
- It highlights the researchers’ ability to uncover previously unknown details about the architecture of a state-of-the-art language model like GPT-3.5-turbo, even without insider access.
- It suggests that a relatively modest budget (for a potential corporate spy or competitor) could be used to extract even more sensitive information about the model’s internal structure.
This underscores the potential vulnerability of these models to “model stealing” attacks and the need for AI companies to develop robust defenses to protect their intellectual property and maintain their competitive edge.
“The attack was possible due to the logit-bias and logprobs that have been made available by these LLM providers.”
Let’s break down the terms “logit-bias” and “logprobs” and then use a simple example to illustrate how they could be used in an attack.
- Logits: In a language model, logits are the raw, unnormalized scores that the model assigns to each possible next word in a sequence. They are the values that come directly from the model’s final layer before being converted into probabilities.
- Logprobs: Short for “log probabilities,” logprobs are the natural logarithm of the probabilities that the model assigns to each possible next word. They are derived from the logits by applying a softmax function, which normalizes the logits into a probability distribution.
- Logit-bias: Logit-bias is a feature offered by some language model APIs that allows users to adjust the logits for specific words before they are converted into probabilities. By increasing or decreasing the logit for a word, users can make that word more or less likely to be generated by the model.
Now, let’s consider an example to see how these concepts could be exploited:
Imagine a language model that can predict the next word in a sentence. Let’s say the model is given the prompt “The cat sat on the” and it has to predict the next word.
The model might assign the following logits to potential next words:
- “mat”: 2.0
- “couch”: 1.5
- “dog”: -1.0
- “car”: -2.0
These logits would then be converted into probabilities (logprobs) using the softmax function, resulting in:
- “mat”: 0.5
- “couch”: 0.3
- “dog”: 0.1
- “car”: 0.1
Now, if the API allows users to access these logprobs and also provides a logit-bias feature, an attacker could potentially exploit this to learn about the model’s inner workings.
For example, the attacker could repeatedly query the model with the same prompt but different logit-bias settings. By observing how the logprobs change in response to specific logit-bias adjustments, the attacker might be able to infer details about the model’s hidden layers, such as the size of the embedding projection layer mentioned in the previous explanation.
In this way, the availability of logprobs and logit-bias features in the API could inadvertently provide a way for attackers to probe and extract information about the model’s architecture and parameters, even if the API does not directly expose those details.
This highlights the importance for LLM providers to carefully consider the security implications of the features they offer through their APIs, as seemingly innocuous features like logprobs and logit-bias could potentially be exploited by sophisticated attackers.
So what could the real-world impact be of such an attack?
If we take a hypothetical (but highly plausible) look at how this type of attack could impact an organization, the ramifications could end up going far beyond just a theft of intellectual property. Given the current AI “gold rush,” organizations are spending a lot of time and money on research and development of AI models to give them an edge against their competitors. If we take the example companies above (Company A and Company B), it wouldn’t be unrealistic to assume an investment of $5 million over two years to develop an advanced AI model for customer behavior prediction.
- Direct Cost: The theft of the model grants Company B access to Company A’s $5 million research and development investment, giving them all the benefits with none of the initial risks. Additionally, Company A now loses the competitive advantage they were counting on to push them ahead of the competition, potentially tanking projected revenue. This has the real-world impact of diminished earnings, but also potentially reducing stock price and/or board of directors confidence.
- Indirect Cost: As Company A is a responsible organization, they, of course, report the breach and theft of their intellectual property, resulting in a customer retention loss due to loss of customer trust. As the $5 million R&D investment was based on future earning potential that has now been diminished, it will take Company A longer to recoup its investment dollars, further reducing overall revenue. Additionally, if Company A discovers that Company B has stolen its intellectual property, the cost of lawsuits could further compound the lost revenue.
What tactics could service providers leveraging proprietary LLMs employ to protect from “model stealing” attacks?
- Rate Limiting and Query Throttling: One way to prevent attackers from making a large number of queries to extract information is to implement rate limiting and query throttling. This means setting a limit on the number of queries a user can make within a given time frame.
- Example: Suppose the vendor sets a limit of 100 queries per minute per user. If an attacker tries to make 1000 queries in a minute to probe the model, the API would block the excess queries and potentially flag the user for suspicious activity.
- API Key Rotation and Monitoring: Vendors can use API keys to track and control access to their models. By regularly rotating API keys and monitoring for unusual usage patterns, they can detect and prevent abuse.
- Example: Let’s say the vendor issues API keys that are valid for 30 days. They also set a daily query limit of 10,000 per key. If a key exceeds this limit, the vendor can investigate and potentially revoke the key if misuse is suspected
- Noise Injection and Rounding: To make it harder for attackers to infer precise details about the model from the logprobs, vendors can add noise to the logprobs or round them to a fixed precision.
- Example: Instead of returning exact logprobs like 0.8147, 0.9058, 0.1270, the vendor could round them to a fixed precision, like 0.81, 0.91, 0.13. This makes it harder for attackers to make precise inferences about the model’s internal state.
- Example: Alternatively, the vendor could add random noise sampled from a normal distribution with mean 0 and standard deviation σ to the logprobs. If X is the original logprob and X’ is the noisy logprob: X’ = X + N(0, σ^2) By carefully tuning σ, the vendor can balance the need for privacy with the impact on model performance.
- Anomaly Detection using Machine Learning: Vendors can use machine learning techniques to detect anomalous query patterns that might indicate a model stealing attempt.
- Example: The vendor could train an autoencoder neural network on a dataset of “normal” user queries. The autoencoder learns to compress and reconstruct normal queries with low error. When a new query comes in, the vendor can feed it through the autoencoder and measure the reconstruction error. If the reconstruction error is high (above some threshold), it suggests the query is anomalous and might be part of a model-stealing attack. The vendor can then investigate or take action. Here, the reconstruction error could be the mean squared error (MSE) between the original query embedding (x) and the reconstructed embedding (x’): MSE = (1/n) * Σ(x – x’)^2 . By setting an appropriate threshold on the MSE, the vendor can flag suspicious queries for further analysis.
These are just a few examples of how LLM providers can protect their models. In practice, a robust defense would likely involve a combination of these and other techniques adapted to the specific needs and threat model of the vendor. The key is to balance security with usability and performance so that the model remains secure without unduly compromising its utility for legitimate users.
Code Security is our Mission
At Qwiet AI, we believe that all security incidents start with code, and we’ve made it our mission to help our customers release secure code quickly and easily. Our AI-powered application security testing platform utilizes a patented scanning method to quickly and accurately find vulnerabilities during the development process. We also provide a full menu of code and AI security consulting services to help organizations safely and ethically integrate AI into their business. And we aren’t stopping there. Join us at the RSA conference in May 2024 for an announcement that will change the way organizations secure code.