
Introduction
Ever wondered what separates a secure application from a vulnerable one from a developer’s perspective? It often boils down to how well you handle user inputs. In this blog, we dive into input validation, an essential yet sometimes overlooked aspect of coding for security. It’s a straightforward guide on the why, how, and what of input validation techniques, offering practical insights and actionable tips. By the end, developers will gain valuable skills to enhance app security and improve overall coding efficiency.
What is Input Validation?
Input validation is like the bouncer at the door of your app, deciding who gets in and who doesn’t based on the rules you’ve set. In the world of cybersecurity, it’s a method used to check every bit of data coming into your application to ensure it’s the right kind, format, and size before letting it through. Think of it as your first line of defense, standing guard to make sure only the good stuff gets in while keeping the potentially harmful data out.
How does input validation do its job, you ask? It’s all about setting clear rules for what’s acceptable. For example, if your app is expecting a phone number, input validation checks to see if the incoming data looks like a phone number and not a sneaky piece of code trying to cause trouble. It’s about distinguishing between what’s safe and what could be an attempt to exploit your app. This way, only data that fits your criteria makes it through, helping to shield your application from various cyber threats.
But input validation isn’t just about keeping the bad guys out. It plays a crucial role in maintaining the overall health of your application. By ensuring that only correctly formatted and expected data is processed, it aids in data sanitization and is a key part of secure coding practices. This means it not only helps in defending against direct attacks but also improves the quality and reliability of the data your application handles, making sure your app runs smoothly and securely.
Why is Input Validation Important?

Why is Input Validation Important?
Without input validation, your application is like a house with the doors wide open, inviting trouble. By ignoring input validation, you’re exposing your app to a variety of risks and vulnerabilities. This negligence can lead to unauthorized access, data leakage, and even complete system compromise. Essentially, input validation acts as a fundamental safeguard, reducing the risk of attacks that exploit the data your application receives, ensuring that only the intended operations are performed, and keeping unwanted visitors out of your system.
Examples of Common Attacks
SQL Injection
| SELECT * FROM users WHERE username = ‘admin’ –‘ AND password = ‘password’ |
This line of code might look harmless at first glance, but it’s actually an SQL injection attack. Here, the attacker tries to bypass authentication by commenting out the rest of the SQL query. Without proper input validation, this input could trick your database into granting unauthorized access to sensitive user information.
Cross-Site Scripting (XSS)
| <script>alert(‘Hacked!’)</script> |
This snippet is a classic example of Cross-Site Scripting (XSS), where an attacker injects malicious scripts into content that’s then shown to other users. Without input validation, this script could execute in a user’s browser, potentially stealing cookies or session tokens, leading to account hijacking.
Command Injection
| ; rm -rf / |
Imagine this input is part of a command your application executes based on user input. It could lead to command injection, where an attacker manages to run their own commands on your server. Without input validation, this could result in the deletion of files or execution of malicious operations.
The impact of successful attacks can be devastating. At best, your data integrity takes a hit; at worst, you’re looking at compromised user privacy and a tarnished organizational reputation. Think about it: news of a data breach can spread like wildfire, shaking user trust and loyalty, sometimes beyond repair.
Types of Input Validation
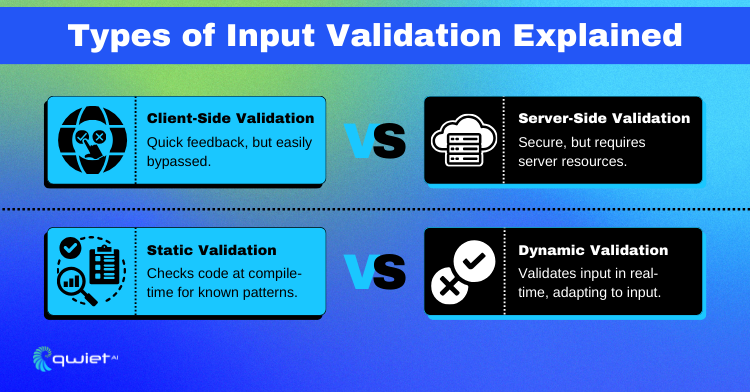
When it comes to input validation, there’s more than one way to skin a cat. Here, we’ll dive into different types of validation and what makes each tick.
Client-Side vs. Server-Side Validation
Client-side validation is like the first checkpoint, happening right in the user’s browser. It’s great for catching simple errors quickly, like forgetting to fill out a form field, and it can make your app feel snappy by reducing unnecessary server requests. However, it’s not foolproof since clever users (or attackers) can bypass it, making server-side validation your app’s real stronghold. Server-side validation is where the rubber meets the road, providing a deeper level of scrutiny that can’t be sidestepped. While it might add a bit of overhead to your server’s workload, it’s non-negotiable for maintaining a secure and reliable application.
Static vs. Dynamic Validation
Static validation is all about setting hard rules. For instance, ensuring an email field contains an “@” symbol. It’s straightforward and works well for checking the format of input against a specific pattern.
Dynamic validation, on the other hand, is more flexible and context-sensitive. It might involve checking if a username is already in use or if a date falls within a certain range.
Use Cases for Static Validation:
Email format verification:
| /^\w+([\.-]?\w+)*@\w+([\.-]?\w+)*(\.\w{2,3})+$/ |
This regular expression ensures the input matches the common structure of an email address.
Password strength check:
| /^(?=.*[A-Za-z])(?=.*\d)[A-Za-z\d]{8,}$/ |
This checks for a minimum of eight characters with at least one letter and one number.
Use Cases for Dynamic Validation:
Username availability:
| if (database.find({ username: userInput })) { alert(‘Username is already taken.’); } |
This snippet checks a database to ensure the username isn’t already taken.
Date range validation:
| if (userDate < startDate || userDate > endDate) { alert(‘Date must be within the allowed range.’); } |
Here, the code ensures a user-selected date falls within an acceptable range.
Whitelisting vs. Blacklisting Approaches in Input Validation
Whitelisting is like having a VIP list for a party; only the inputs that match your specific criteria are allowed in. This approach is considered safer because it automatically blocks anything unexpected. You define what is acceptable, and everything else, by default, is rejected.
Blacklisting, on the other hand, tries to identify and block known bad inputs. It’s like telling the bouncer at your party to keep an eye out for a few troublemakers. While it can be useful for filtering out known attack patterns, it’s not as secure as whitelisting. New exploits and attack vectors that aren’t on your blacklist can slip through, potentially leaving your app vulnerable.
Best Practices Implementing Input Validation

Adopting a defense-in-depth strategy is crucial for robust app security. This means you should incorporate both client-side and server-side validation. By doing so, you catch simple issues before they hit your server, improving user experience and reducing server load. However, the server-side validation is your safety net against more sophisticated attacks, as it’s harder for attackers to bypass.
Guidelines for Effective Validation
For developers looking to implement effective input validation, here are some actionable steps:
Use Regular Expressions for Pattern Matching:
Regular expressions are powerful tools for validating the format of user inputs. For example, to ensure an email address is in the correct format, use a regular expression that matches the general pattern of email addresses. This can prevent users from entering improperly formatted emails, which is a common issue.
Example: When expecting an email input, craft a regular expression that checks for the presence of an “@” symbol and a domain, ensuring the input is in the form of an email address.
Perform Data Type Checks:
Make sure the data submitted matches the expected type. If you’re expecting a numerical input, verify the data is indeed a number. This simple check can prevent many types of errors and security vulnerabilities.
Example: Use type-checking functions or methods provided by your programming language to ensure an input meant to be a date or a number isn’t submitted as a string of text.
Implement Length Checks:
Define maximum (and sometimes minimum) lengths for your inputs to protect against buffer overflow attacks and ensure data integrity. This helps prevent attackers from overwhelming your system with excessively long inputs.
Example: Set a reasonable character limit on user inputs like names and messages. For a username, a maximum of 30 characters might be sufficient, preventing excessively long inputs that could cause issues.
Sanitize Inputs to Remove or Encode Illegal Characters:
Input sanitization involves stripping out or encoding characters that could be used in injection attacks. This step is critical for maintaining the security of your application.
Example: When accepting user-generated content that will be displayed on your website, encode special HTML characters to prevent cross-site scripting (XSS) attacks.
Conclusion
So, we’ve gone through Output Encoding, why it matters, and how to do it with examples from different coding languages. Plus, we discussed why keeping an eye on your security with regular checks is a game-changer. In summary, Output Encoding plays a crucial role in securing web applications by preventing malicious actors from compromising your site and the safety of your users. If enhancing your App’s security is a priority, we invite you to book a demo today to see how Qwiet can secure your codebase.