

Key Takeaways
- As a software developer, security professional, or technical decision-maker, it is essential to recognize that internal code is not inherently secure; it is often unscanned. Custom frameworks and in-house libraries frequently do not appear in public CVE databases and typically do not match known patterns, making them invisible to most rule-based application security (AppSec) tools. Your role in identifying and addressing these vulnerabilities is key.
- Rule-based scanners miss custom behavior because they can’t infer intent. Traditional SAST tools rely on predefined signatures. When logic is wrapped in internal helpers or custom abstractions, these tools can’t determine whether data is being misused.
- Graph-based analysis, a method that exposes behavior across layers and functions, is the core of Qwiet’s approach. Qwiet builds a comprehensive behavioral map of your application, revealing how data flows across internal utilities—even when the code structure doesn’t conform to conventional patterns. It’s like creating a map of your code’s behavior, showing how different parts interact and where potential vulnerabilities might be hiding.
Introduction
Custom frameworks often feel safer than they are. When code is built in-house, teams trust it more because it’s familiar and under their direct control. But that sense of safety can be misleading. Internal systems don’t trigger CVEs; traditional AppSec tools rarely understand them beyond surface syntax. Just because code is proprietary doesn’t mean it’s been adequately validated. It often means it hasn’t been scanned effectively at all. This continues the theme from the first article: rule-based scanners create a false sense of coverage. They identify known issues but overlook the risks that arise from custom behavior. And when your stack includes internal libraries or homegrown middleware, those gaps get larger.
This article will explore why custom frameworks become blind spots, how traditional tools fall short, and how graph-based analysis can surface real issues hidden in code you thought was safe.
Why Internal Code is a Blind Spot

Most security scanners are built around the public attack surface. They lean heavily on known CVEs, standard sink functions, and standardized libraries. That model works well for identifying vulnerabilities in third-party code, but it begins to break down when the focus shifts to internal frameworks.
Custom authentication systems, proprietary middleware, or in-house utilities often lack metadata, do not map to public CVEs, or do not match any rulebook entries. As a result, they rarely get flagged, even when the risk is real.
Developers often assume their code is inherently safer because they control it. There’s a sense that if it wasn’t imported from somewhere else, it’s already been vetted. However, the internal code is rarely subject to the same scrutiny. It’s often undocumented, loosely governed, and highly dependent on tribal knowledge. That makes it easy for assumptions to creep in about where validation happens, who can call a method, or how something behaves when passed untrusted input. Over time, those assumptions get codified into the framework’s logic, making them harder to detect and validate during security reviews.
The risk isn’t theoretical. Internal logging tools that modify headers, helper functions that interact with the file system, or custom routers that bypass access checks can introduce security gaps. But scanners won’t detect them unless they’ve been explicitly told what to look for. And in most environments, that doesn’t happen. This underscores the urgent need for a more comprehensive approach to security.
These internal patterns, such as custom function names, internally defined wrappers, or proprietary abstractions, deviate from the scanners’ expectations. Traditional tools often fail to detect serious vulnerabilities because they don’t track how custom components are used throughout the application, especially when those components modify data, bypass controls, or influence sensitive behavior in other layers.
Where Traditional Tools Fail
Rule-based static analysis engines operate by detecting known patterns tied to insecure behavior. These patterns are often mapped to external CVEs or commonly used functions and libraries with well-defined security implications. However, these tools have limitations when it comes to evaluating custom code.
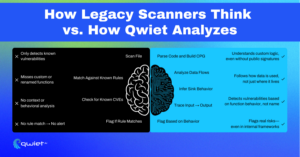
Rule-based static analysis engines operate by detecting known patterns tied to insecure behavior. These patterns are often mapped to external CVEs or commonly used functions and libraries with well-defined security implications.
When code diverges from those assumptions using custom function names, internally defined wrappers, or proprietary abstractions, the scanner lacks the ‘semantic hooks’ to evaluate behavior. The scanner lacks the necessary tools to comprehend what the code is doing. Without a known label or external metadata, it can’t determine a function’s purpose.
Security tools that depend solely on signatures and surface-level syntax lack the semantic resolution to track logic through in-house systems. For example, a function like internalCommandExec() that wraps a shell call won’t be flagged if the tool doesn’t recognize it as a sink.
Similarly, internal routers that implicitly skip middleware or authorization checks will not appear risky to a scanner that cannot evaluate control flow across abstraction layers. Even when data flows from a user input source into these operations, the absence of predefined markers means the tool sees it as benign.
This limitation becomes more pronounced in environments where developers build internal frameworks tailored to specific use cases. It’s common to see security decisions embedded deep in helper decisions that static analysis can’t verify without understanding intent and behavior.
The scanner can’t reason about the code’s impact when that context is missing. That’s how privilege checks, unsafe I/O operations, or sensitive logging paths slip through without detection. It’s not a failure in scanning; it’s a mismatch between how the tool interprets the code and how it is written.
How Graph-Based Analysis Exposes the Truth

Qwiet doesn’t rely on signatures or hardcoded rules to find vulnerabilities. Instead, it builds a Code Property Graph, a unified structure connecting syntax, control flow, and data flow across your codebase.
That means it can track how values are transferred, decisions are made, and where inputs ultimately end up. It’s less about checking whether a specific API is dangerous and more about understanding how your code behaves across files, layers, and services.
This analysis is particularly valuable in environments where internal tools are heavily utilized. Qwiet doesn’t need to recognize a function’s name to know it’s risky. Suppose an internal method, such as runCommandInternal(), takes user input and passes it to a shell execution layer, even if it’s wrapped and abstracted multiple times. In that case, Qwiet can follow that chain and identify the sink behavior based on how data flows and what the function does with it.
It also catches more subtle paths. If input from an HTTP request eventually flows into a logging tool that writes directly to disk, Qwiet considers that a potential file write operation, even if the logger is not flagged in any rule set. This context-driven detection enables it to surface vulnerabilities in code that static tools often overlook, especially when the risks are concealed within custom logic or internal abstractions.
The benefit is not just better detection but earlier visibility. Qwiet flags these behaviors before they reach production without needing someone to create rules for every custom function manually. That’s a massive shift from pattern matching to actual behavioral understanding, making proactive detection possible in large, fast-moving codebases where internal tooling is the norm.
Securing the Frameworks You Build
Internal frameworks deserve the same scrutiny as external dependencies. Just because your team built the code doesn’t mean it’s been fully evaluated from a security perspective. Treating internal libraries like third-party packages, isolating their trust boundaries, reviewing how they are used, and scanning them with the same frequency goes a long way in surfacing risks that would otherwise be ignored.
One of the most effective steps is documenting how data is meant to move through these internal components. This includes determining what inputs are considered safe, where validation is expected, and what assumptions are built into each interface. Without that clarity, downstream code can easily misuse the library in ways that were never intended, especially when different teams adopt the same utilities without context.
Signature-based scanning can’t keep up with custom behavior. To effectively cover internal frameworks, you need tools to understand what the code is doing, not just how it looks. Behavioral analysis and graph-based detection are far better suited for tracking how data flows through helpers, wrappers, and deeply integrated utilities. That context is where real validation happens, and it’s the only reliable way to surface logic gaps in frameworks that don’t follow external conventions.
Security practices need to evolve in tandem with the systems they protect. Static rules tied to naming patterns or known sinks will always lag behind internal innovation. If your team is building tools to move faster, your scanning needs to do the same. That means reassessing how you validate and monitor the libraries you own, not because they’re public or widely reused, but because they have real influence over how your app behaves in production.
Conclusion
Assuming internal code is secure just because it’s familiar creates risk. In-house frameworks often skip the scrutiny applied to external code, leaving gaps that static tools tuned for public patterns won’t catch. Rule-based scanners detect what they recognize, which rarely includes the logic unique to your environment. Large portions of your code remain unreviewed without understanding how internal tools handle data or enforce boundaries. Qwiet takes a different path. Its graph-based engine models full application behavior, uncovering risks that signature-driven tools overlook.
Book a demo with Qwiet to see how we surface what others miss and bring visibility to the code you depend on most.
FAQs
Why do traditional AppSec tools miss vulnerabilities in internal frameworks?
Traditional AppSec tools rely on known patterns and public CVE databases. Internal frameworks often employ custom logic and naming, which means scanners do not recognize them as risky, even when they expose sensitive functionality.
How does Qwiet detect vulnerabilities in custom or in-house code?
Qwiet uses graph-based code analysis to model syntax, control flow, and data flow across the application. It detects risky behavior by analyzing data flows, rather than relying on predefined patterns or function names.
Can static scanners identify custom authorization or validation gaps?
Most static tools cannot identify business logic or access control gaps unless tied to known APIs or code patterns. Custom auth layers and validation logic often go unflagged without behavior-aware analysis.
What are the risks of assuming internal code is secure?
Assuming internal code is secure can lead to undetected vulnerabilities. Without thorough, context-aware scanning, internal functions may introduce risks such as unsafe file access, privilege escalation, or missing access controls, which are often overlooked by signature-based tools.