
As we embark on this new chapter in application security, it’s important to understand how AI and machine learning can provide greater understanding and insight into vulnerabilities than older methods of detection. In this article we will cover the following:
- The risk of using vulnerable dependencies (directly or transitively)
- Not all vulnerabilities pose risk. Why not?
- The drawbacks of shallow analysis by security vendors leading to many false positives
- Motivating by example (CVE-2021-29425)
- How Code Graph aided by Machine Learning can pinpoint upstream projects with call-paths leading to vulnerable methods in downstream libraries
The past two decades have witnessed a surge of software reuse. An increasing number of open-source dependencies (OSS) have been released under open-source licenses, and the development of such libraries heavily depend on the infrastructures or functional components of each other. The numerous diverse libraries and their complex dependency relations naturally form large-scale social-technical ecosystems (Maven for Java, npm for JavaScript, etc…). As an example, the Java ecosystem, managed mainly by Maven, has indexed over 9.51 million third-party libraries, which have been facilitating the development of Java projects significantly for a long period
Unfortunately, OSS also suffer from various vulnerability issues, and the number of disclosed vulnerabilities has been increasing steadily since late 2000s. Such vulnerabilities can pose significant security threats to the whole ecosystem, not only to the vulnerable libraries themselves, but also to the corresponding downstream projects (i.e., if we regard a library/application as an upstream, those libraries/application depend on this upstream are denoted as the corresponding downstream). It has been estimated that around 74.95% of the OSS that contain vulnerabilities are widely utilized by other libraries. For instance, the recently spotted vulnerabilities in Apache Log4j2, have affected over 35,000 downstream Java packages, amounting to over 8% of the Maven ecosystem. The growing trend of the vulnerabilities discovered in open-source libraries results in the inclusion of “vulnerable and outdated components” in the OWASP Top 10 Web Application Security Risks, which is still ranked at sixth currently.
The basic intuition behind most of the vendors and open source tools is to perform Software Composition Analysis (SCA) by analyzing the Software Bill of Materials (SBOM) — dependency configuration file or the information gathered during compilation, and then search for vulnerable components referring to existing vulnerability databases (e.g., National Vulnerability Database (NVD)). Warnings will be reported to developers once known vulnerable dependencies are detected, and developers are suggested to take mitigation actions such as upgrading the dependency to non-vulnerable versions.
Listed below is an example of a expression based pattern matching policy created by a vendor https://gitlab.com/gitlab-org/security-products/analyzers/semgrep/-/blob/main/rules/find_sec_bugs.yml#L969-978
Such tools often generate a high number of false alerts since they mainly work at a coarse granularity without analyzing whether the upstream vulnerabilities will actually affect the corresponding downstream projects. Such a high rate of false positives will annoy developers, and our data also confirms that some developers are bothered by such imprecise warnings and take unnecessary actions simply to get rid of such warnings. Even worse, such warnings will lead to unwanted upgrade of dependencies, which might further introduce other dependency conflicts or incompatibility issues. Therefore, tools that are able to assess the security threats of upstream vulnerabilities to downstream projects more precisely are much desired.
Our main objective is to understand the risk of upstream vulnerabilities being exploited in downstream projects, and to develop a method for assessing this likelihood. In particular, we investigate from multiple aspects, including whether the downstream projects are reachable to upstream vulnerabilities as well as the complexity of those constraints along the reachable paths.
Motivating example to illustrate reachability
We use vulnerability CVE-2021-29425 exposed in project commons-io as an example to illustrate impact via reachability. The vulnerability affects the versions <= 2.7 of commons-io library. It is introduced since developers forget to check the validity of the host name in function getPrefixLength(), which exhibits a high chance of introducing a path traversal vulnerability `../../../etc/.. . Project commons-io, as an upstream library, has been utilized by 23,974 other projects (denoted as the downstream projects) in the ecosystem as indexed by Maven, and among which over 14,000 of them utilize those versions that are affected by CVE-2021-29425. For the affected version 2.4 only, it has by 4,386 downstream projects.
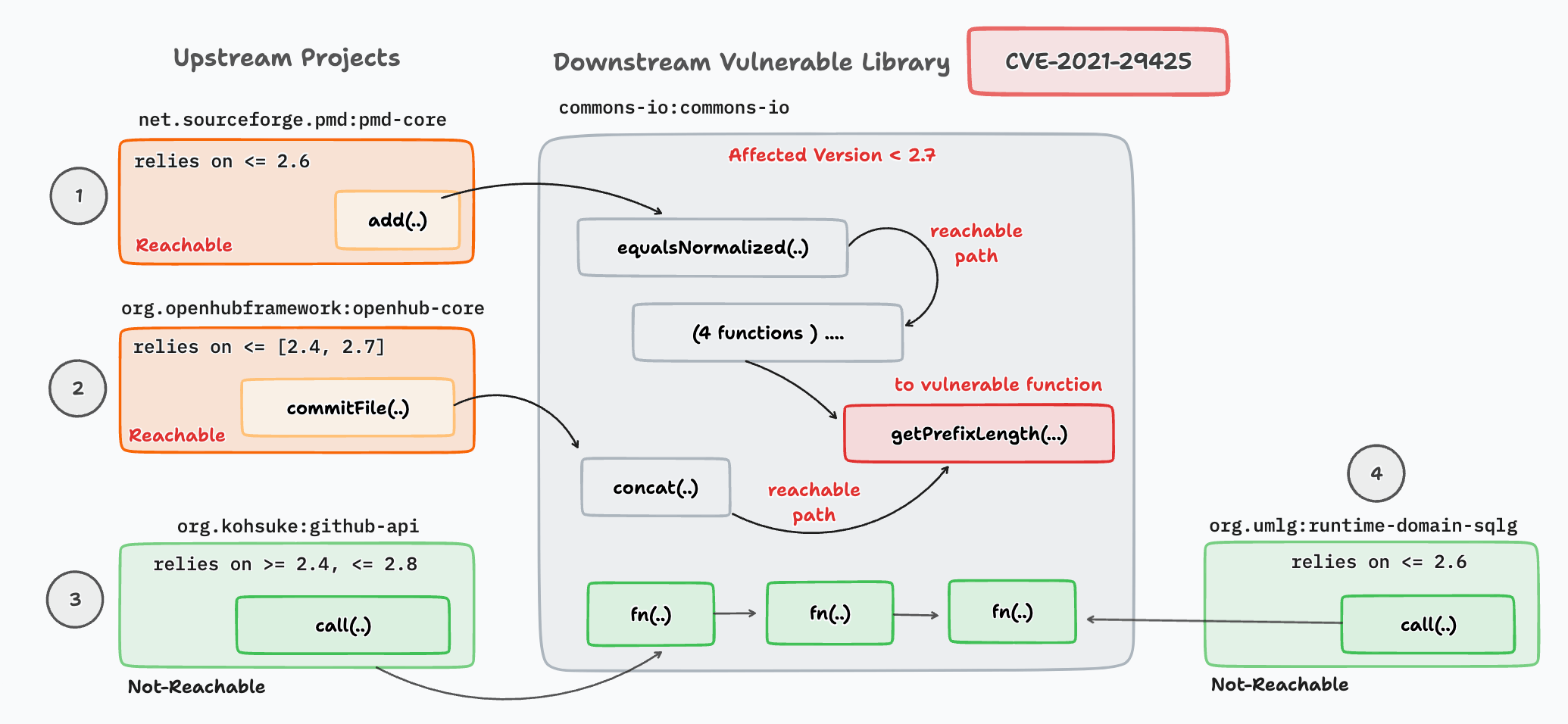
First, certain downstream projects that rely on a vulnerable upstream are actually not threatened by the vulnerability. As shown in Figure above, although all the four downstream projects depend on the vulnerable version of commons-io (i.e., version 2.4), not all of them can actually reach the vulnerable code.
- For pmd-core and openhub-core, they can reach the vulnerable function getPrefixLength() transitively.
- On the contrary, the other two projects (i.e., github-api and runtime-domain-sqlg) cannot access the vulnerable function by all means.
A Majority of the SCA vendors will report for all the downstream projects to be vulnerable since they ignore the reachability to the vulnerable code, thus resulting in false positives.
Second, even if the vulnerable function is reachable from downstream projects, the chance of exploitability is different. As per Figure above the corresponding call graphs for the two projects that are reachable to the vulnerable function getPrefixLength. As can be seen, the downstream transitively invoke the vulnerable function through other APIs such as equalsNormalized and concat. In particular, for pmd-core, it passes through four other functions to reach the vulnerable function while openhub-core only passes through one. Along the reachable call path, various constraints are required to be satisfied to reach the vulnerable code. Such constraints along the path restrain the vulnerability from being exploited in downstream projects, and thus the complexity of them can reflect the extent to which the downstream is threatened by the vulnerability.
Remediate what matters — using Code Property Graphs aided by ML
Continuously monitoring programs and its supply chain (OSS dependencies) for violations of code-level security policies introduces two main challenges. First, high-level information flows need to be derived by reasoning about the interplay of low-level data flows and call chains from upstream projects to downstream dependencies. Second, we require a mechanism for specifying and evaluating security policies on high-level information flows. We address these problems by implementing the four-step procedure illustrated in the image below.
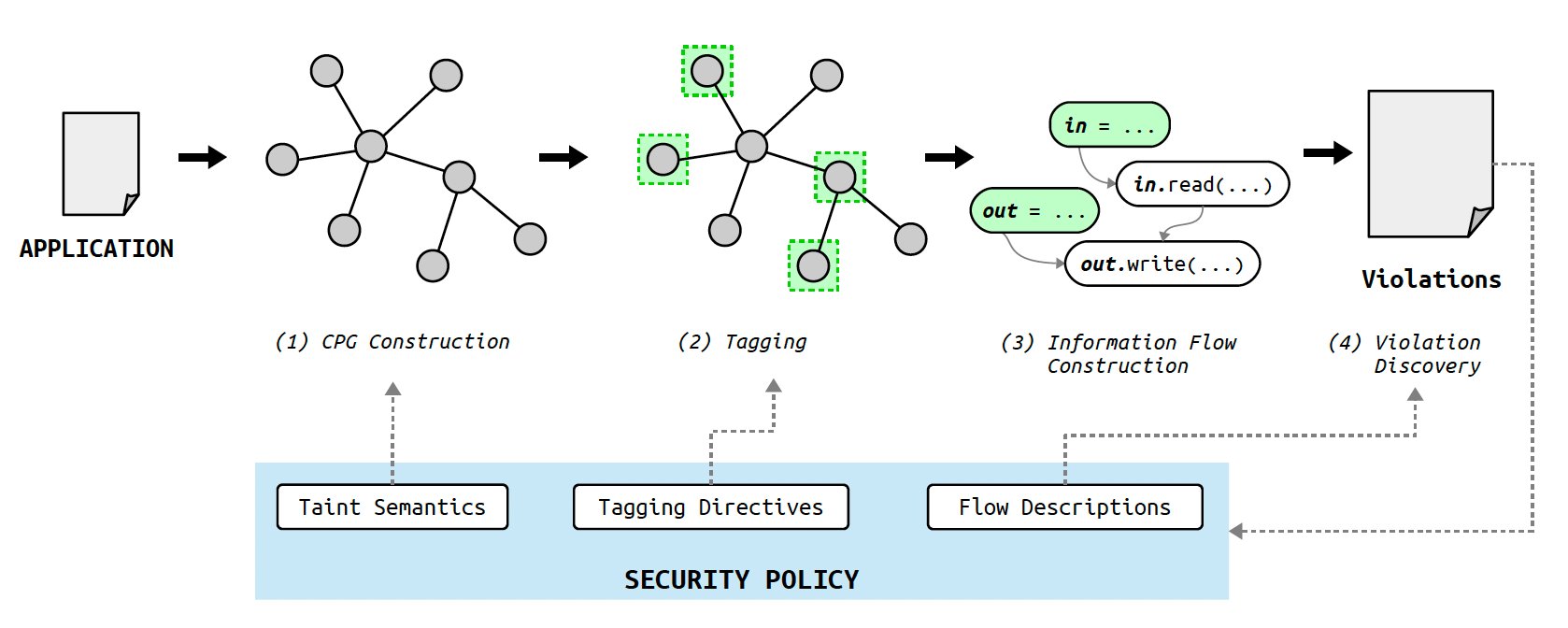
- Semantic code property graph construction. We begin by constructing an intermediate code representation, the semantic code property graph, from the program code and data-flow semantics.
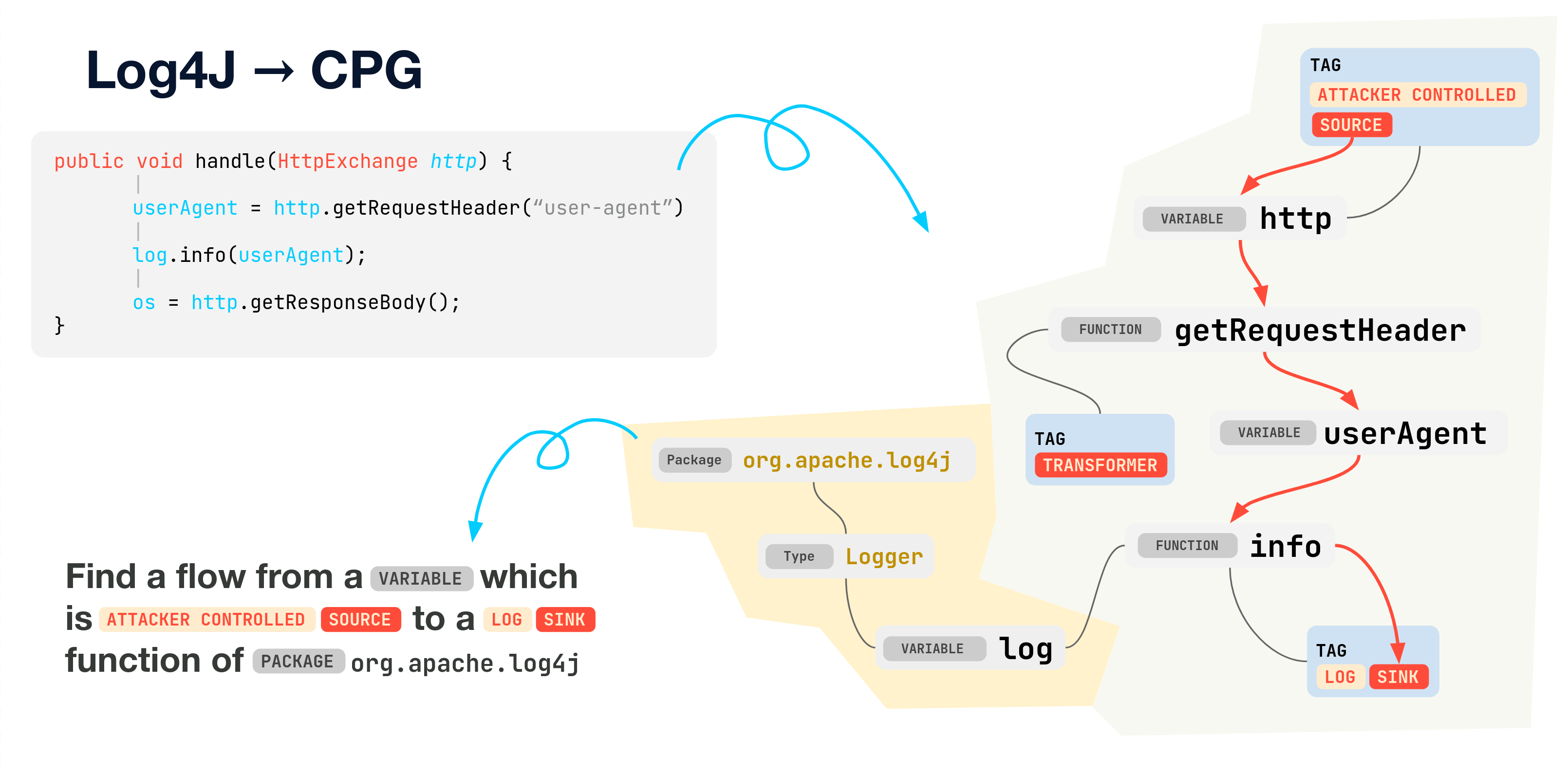
- Tagging of data entry points and operations. Tagging directives contained in the security policy are subsequently applied to mark code locations where data enters the application, is operated on, or used in sensitive operations. A tag is simply a key-value pair (k,v), where k is an element from a key space, and v is a string. Some of tagging directives are illustrated below
- Exposed functions. We tag functions that can be triggered by the attacker, e.g., HTTP and RPC handlers. For these methods, we tag parameters that are controlled by the attacker.
- Read operations. Functions that introduce data into the application, e.g., read operations on streams or database handles, and the corresponding output parameters holding data thus read are tagged.
- Write operations. Analogously, functions that write or transmit data to storage or other components and the input parameters holding the transmitted data are tagged. Examples are functions that emit database queries, specify a resource handler, or write data to a file.
- Transformations. Functions that transform data, the input parameter they transform, and the output parameter holding the transformed data are tagged. Examples are encoding and encryption routines, but also sanitizers
- Descriptors. For all read operations, write operations and transformations, parameters that configure method behavior are tagged as descriptors, e.g., the instance parameter of a read operation on a data stream is a descriptor, as is the filename in a file-open operation.
- Information-flow modeling. With tags in place, we proceed to carry out data-flow and call chain analysis and combine results to determine high-level information flows.
- Violation discovery. Finally, we evaluate flow descriptions on information flows to determine policy violations.
- We encode rules for tagging of methods and parameters as tagging directives and include them in the security policy. To this end, we define a high-level tagging language, the simplified grammar of which is shown below

With data-flow semantics and tagging directives applied to the code property graph, we are ready to determine high-level information flows. The overall idea of this concept is to combine multiple data flows and call chains (originating at an upstream project and terminating at a downstream library) into a single logical information flow. Given the immense number of dependency libraries with ever-changing code bases maintaining an accurate, up-to-date security policy is a tall order. By leveraging the information-rich and extensible format of CPGs, machine learning models can tag directives with a level of nuance previously reserved for security experts while being orders of magnitude faster than ever before. With this high level of detail applied across the board, vulnerable data flows from upstream projects to downstream dependencies that previously would have been missed can now be identified and fixed before they get exploited. While CPGs provide a rich playing field for machine learning models, the same versatility that allows them to represent any arbitrary piece of code can present challenges at first when utilizing ML. Classical machine learning models rely on being presented with the same sized data structure for every sample, but code property graphs can contain any number of nodes with any combination of edges. To support this varied data structure, the directive tagging model uses the message passing graph neural network framework incorporating the topology of the input graph into the topology of the model at run time. Attention-based convolution layers can then handle node and graph-level prediction targets while a custom extension to the message passing framework developed in-house at Qwiet AI enables prediction on individual variables within a CPG. These methods allow directive tagging to be performed accurately on previously unseen codebases, enabling generalization from open source to proprietary code without issue, effectively combining the power of ML with the flexibility of a CPG. Natural Language based policies can thus be formulated using a higher level language which leverages the tagging directives to model information flow.
As we’ve discussed today, the proliferation of reused OSS is only exacerbating the spread of vulnerabilities in software and shows no signs of slowing down. This could of course lead to overtaxed development teams chasing countless fixes if you are properly prioritizing those fixes based on not only severity, but also reachability. As you wade further in to both upstream and downstream vulnerabilities, AI becomes a much more important tool to quickly discover and differentiate between the issues that must be addressed immediately and those that while technically a vulnerability, don’t pose a reachable threat. We are just scratching the surface of ML applied to code science but with the application of Code Property Graphs over years of open source and custom code, Qwiet AI can finally start to detect the undetectable and eventually “Prevent the Unpreventable”. We also need to be keeping an eye on the future of software development. With the advent of easily accessible AI tools, it’s not unrealistic to see a future where the majority of code is written by AI, potentially making every piece of software custom and unique. Given that AI coding tools would be most likely trained on existing OSS, we should expect to see vulnerable code being used just as much as secure code, making the use of AI in your AppSec platform a “must have”, not a “nice to have”. This is where we have the opportunity to eradicate exploits and malware, by taking code security to the beginning of the security problem and preventing not just zero-days but preZero-days.