
Introduction
GraphQL: A powerful querying language that allows developers to ask for exactly what they need, nothing more, nothing less. While it’s renowned for its efficiency and flexibility, it’s crucial to acknowledge the associated security implications. It’s like the double-edged sword that, if not handled with caution, can lead to potential vulnerabilities. Let’s explore the myriad ways to secure GraphQL APIs and ward off common security vulnerabilities.
Understanding GraphQL
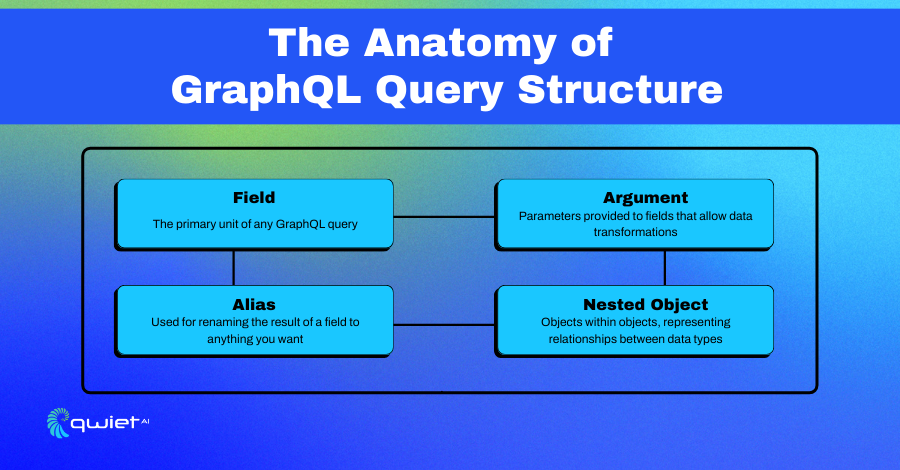
GraphQL is a modern technology used in web development that changes how data is communicated between the parts of a web application. It allows the client, such as a user’s browser, to ask for specific information from the server, ensuring that only the necessary data is transferred. This is beneficial because it can make websites and applications run faster and more efficiently, as no unnecessary information is sent over the internet.
The technology itself is built around a schema, a kind of blueprint that defines what kind of data can be asked for and how it should be organized. Developers create these schemas as a guideline, ensuring that everyone can understand and follow the structure of the data being exchanged.
However, GraphQL’s flexibility also brings challenges, particularly in security. It allows for very detailed and specific queries, but if not managed correctly, this can expose sensitive information or make the system vulnerable to attacks.
It’s essential for developers to be proactive, implementing practices that secure the data being exchanged, ensuring that it’s used safely and correctly. By doing this, developers can make the most of what GraphQL offers, maximizing its benefits while minimizing risks.
Common GraphQL Vulnerabilities

Inadequate Depth Limiting
Depth limiting is an essential security control in GraphQL APIs, ensuring that queries don’t become excessively nested and complex, thereby safeguarding the server from potential attacks and performance issues. Let’s dissect this with an example.
Consider a system where each author has posts, and each post is linked back to an author. A malicious user could exploit the absence of depth limiting by crafting a recursive query that indefinitely nests, querying authors and posts repetitively, like in the following example:
| query { author { posts { author { posts { author { posts { … // Continues indefinitely } } } } } } } |
Such a query can overwhelm the server by consuming significant resources, leading to slow performance or even causing the system to crash, making it inaccessible to legitimate users.
To combat this vulnerability, developers should implement depth limiting in the GraphQL schema to restrict how deeply queries can be nested. Here is a simple code snippet to enforce depth limiting using the graphql-depth-limit library:
| import depthLimit from ‘graphql-depth-limit’; import { createServer } from ‘apollo-server’; const server = createServer({ typeDefs, resolvers, validationRules: [depthLimit(5)] // Limiting the depth to 5 levels }); server.listen().then(({ url }) => { console.log(`Server ready at ${url}`); }); |
In the code above, a depth limit of 5 levels has been imposed, which means any query nested deeper than 5 levels will be rejected, thus protecting the server from overly complex and potentially harmful queries.
Countermeasures:
- Rate Limiting: Limit the number of API requests users can make in a set timeframe to prevent abuse and overload.
- Query Complexity Analysis: Assign and limit the computational cost of each query to prevent excessively complicated queries from overburdening the system.
- Query Whitelisting: Only allow predetermined, safe queries to be executed, preventing malicious or arbitrary queries.
- Authentication and Authorization: Ensure that only approved users can access certain data, and limit actions based on user roles and permissions.
Excessive Resource Requests
In GraphQL, you can ask the server for various pieces of data in one single request. This is a powerful feature, but it can sometimes be too much for the server to handle efficiently. It’s like asking someone to carry all your grocery bags at once; if there are too many bags, it could overwhelm them.
Look at this example:
| query { posts { title content comments } users { name posts comments } } |
Here, the query is like a question we’re asking the server: “Can you give me information about posts and users, including the title, content, and comments of posts, and the names of users?” This request is quite big and could make the server work really hard to get all this information, potentially slowing it down.
To manage this and prevent slowing down the server, we can put some rules or limits on how much information a single query can ask for. By doing this, we can make sure the server doesn’t get overwhelmed with too much work, helping it to run smoothly and efficiently.
Countermeasures:
- Pagination: Limit the number of items returned in a response to manage data effectively.
- Timeouts: Set maximum durations for queries to prevent them from running indefinitely.
- Throttling: Limit user queries within a certain timeframe to prevent system overload.
- Schema Design: Strategically structure data and relations to minimize vulnerability.
- Cost Analysis: Utilize tools to assess and limit the resources consumed by each query.
Best Practices for GraphQL Security
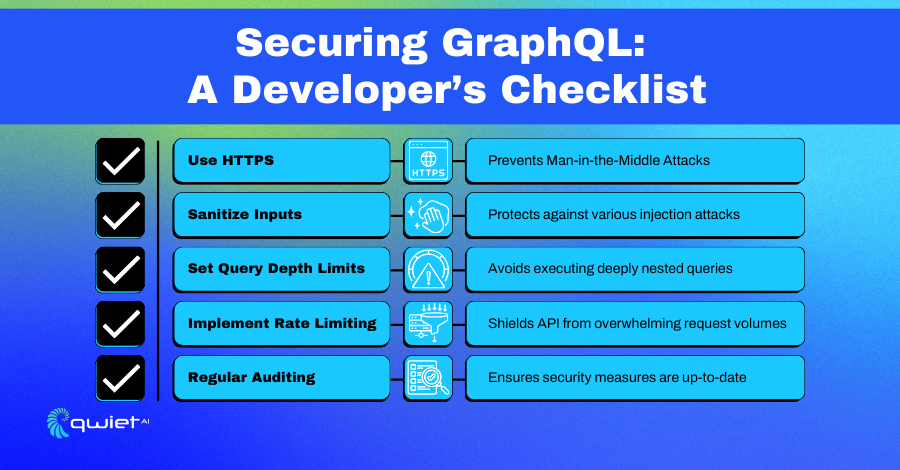
Use HTTPS
HTTPS (Hypertext Transfer Protocol Secure) is like having a secure and private conversation in a crowded room. It ensures that the information exchanged between a user’s device and the server is encrypted and secure, making it unreadable to any unintended recipients trying to intercept the data.
When you use HTTPS, it protects your API against attacks such as “man-in-the-middle,” where attackers could potentially eavesdrop or tamper with the data being sent or received. Always enable HTTPS to create a secure channel that guards the data integrity and confidentiality of the information exchanged in your GraphQL API.
Sanitize Inputs
Sanitizing inputs is like having a security guard at the door of a building, ensuring that nothing harmful enters. When users interact with your application, they provide various inputs.
If unchecked, malicious users could insert harmful data, leading to attacks such as data injection. Sanitizing means cleaning or filtering the user inputs to ensure that only safe and relevant data gets processed.
| import { sanitize } from ‘some-sanitizer-library’; // Sanitize all user inputs const sanitizedInput = sanitize(userInput); |
Here, a sanitization library is used to clean all user inputs, mitigating the risk of injection attacks.
Maintain Simplicity
Keeping your GraphQL schema and queries simple is like keeping your room tidy and organized. It’s easier to find what you need and there’s less clutter. A simpler, well-organized GraphQL schema is less likely to have vulnerabilities or security loopholes.
By keeping your schema and queries clear, concise, and focused on what is necessary, you reduce the chances of encountering issues or vulnerabilities, making your API more secure and easier to manage and maintain. Aim for simplicity and clarity in designing your GraphQL elements to maintain a robust and secure environment.
Conclusion
Ensure your GraphQL APIs are secure and resilient by carefully managing each component. Strike a balance between flexibility and robust security to safeguard against threats. Enhance your API defenses—book in a call to our team today to see how Qwiet can help your bolster your API’s security posture.